When you see an action picture, say a ball in mid-air or a car driving on the highway in the middle of the desert, your mind is very good at filling in the blanks. Namely, it’s a no-brainer that the ball is going to hit the ground or the car will continue to drive in the direction it’s facing. For a machine, though, predicting what happens next can be very difficult. In fact, many experts in the field of artificial intelligence think this is one of the missing pieces of the puzzle which when completed might usher in the age of thinking machines. Not reactive, calculated machines like we have today — real thinking machines that in many ways are indistinguishable from us.
Researchers at MIT are helping bridge the gap in this field with a novel machine learning algorithm that can create videos out of still images.
“The basic idea behind the approach is to compete two deep networks against each other. One network (“the generator”) tries to generate a synthetic video, and another network (“the discriminator”) tries to discriminate synthetic versus real videos. The generator is trained to fool the discriminator,” the researchers wrote.
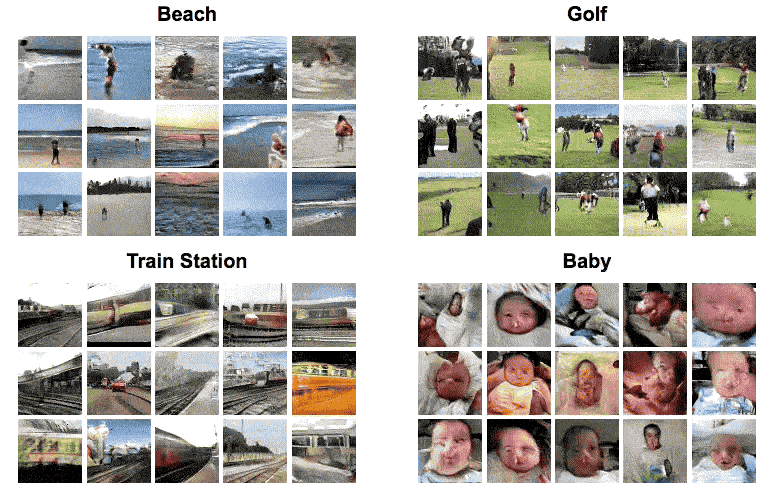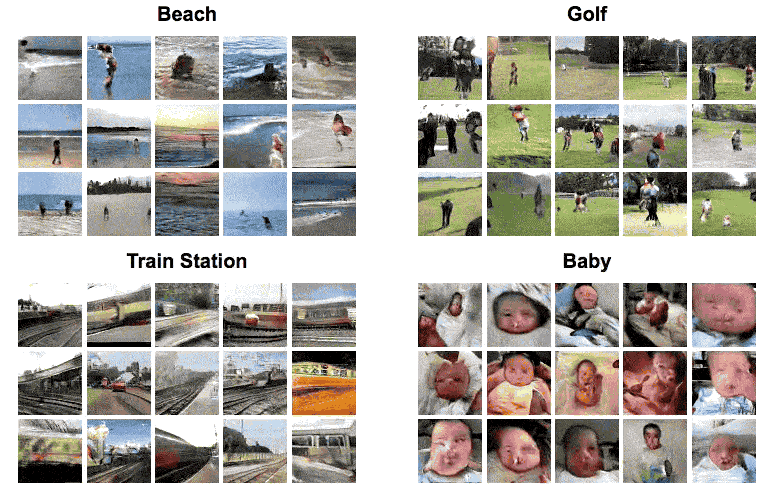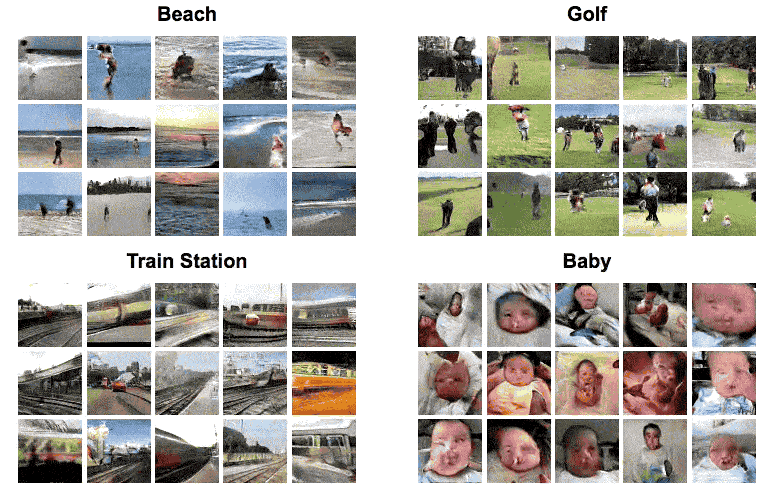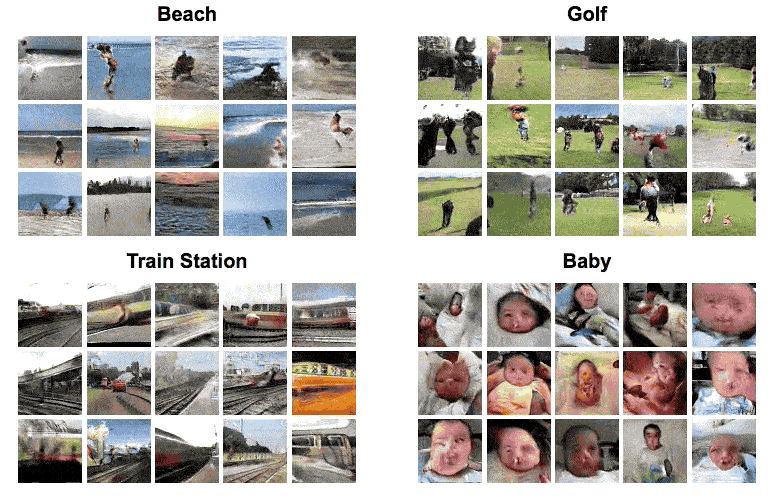
The neural net, comprised of artificial neural networks, was trained by being fed 2 million videos downloaded from Flickr, sorted by four types of scenes: golf, beach, train and baby. Based on what the neural net learned from these videos, the machine could then complete a still picture by adding self-generated frames essentially predicting what happens next (the GIF below). The same machine could also generate new videos that resemble the scenes from the still picture (first GIF in this article).

The feat, in itself, is terrifically impressive. After all, it’s all self-generated by a machine. But that’s not to say that the neural net’s limitations don’t show. It’s enough to take a close look at the generated animated graphics for a couple seconds to spot all sorts of oddities from deformed babies, to warping trains, to the worst golf swings in history. The MIT researchers themselves identified the following limitations:
-
The generations are usually distinguishable from real videos. They are also fairly low resolution: 64×64 for 32 frames.
-
Evaluation of generative models is hard. We used a psychophysical 2AFC test on Mechanical Turk asking workers “Which video is more realistic?” We think this evaluation is okay, but it is important for the community to settle on robust automatic evaluation metrics.
-
For better generations, we automatically filtered videos by scene category and trained a separate model per category. We used the PlacesCNN on the first few frames to get scene categories.
-
The future extrapolations do not always match the first frame very well, which may happen because the bottleneck is too strong.
We get the idea, though. Coupled with other developments, like another machine developed at one of MIT’s labs that can predict if a hug or high-five will happen, things seem to be shaping up pretty nicely.
via The Verge
Was this helpful?


