As humans, we’re pretty good at anticipating things, but that’s much harder for robots. If you walk down the street and see two people meeting in front of a café, you know they’ll shake hands or even hug a few seconds later, depending on how close their relationship is. We, humans, sense this sort of stuff very easily, and now some robots can too.

MIT used deep-learning algorithms — neural networks that teach computers to find patterns by themselves from an ocean of data — to build an artificial intelligence which can predict what action will occur next, starting from nothing but a still frame. Each of these networks was programmed to classify an action as either a hug, handshake, high-five, or kiss. These networks are then merged to predict what happens next. The demonstration video below is telling.
To train the algorithm, the researchers fed more than 600 hours of video footage from YouTube but also the complete series of “The Office” and “Desperate Housewives.” When this was tested, it could correctly predict 43 percent of the time what action would happen in the next one second.
In a second test, the algorithm was shown a frame from a video and asked to predict what object would appear five seconds later. For instance, a frame might show a person attempting to open a microwave. Inside might be some leftover pasta from last night, a coffee mug and so on.
The algorithm correctly predicted what object appeared 11 percent of the time. That might not sound impressive, but it’s still 30 percent better than the baseline measurement and some of its guesses were better than those made by some people. When the same test was given to people, the subjects were right only 71 percent of the time.
“There’s a lot of subtlety to understanding and forecasting human interactions,” says Carl Vondrick, a PhD student at MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL). “We hope to be able to work off of this example to be able to soon predict even more complex tasks.”
“I’m excited to see how much better the algorithms get if we can feed them a lifetime’s worth of videos,” Vondrick added. “We might see some significant improvements that would get us closer to using predictive-vision in real-world situations.”
For now, there’s no practical outcome in mind for this deep-learning algorithm, but the researchers say their present work might one day lead to better household robots that can work better with humans by vanquishing some of the inherent awkwardness.
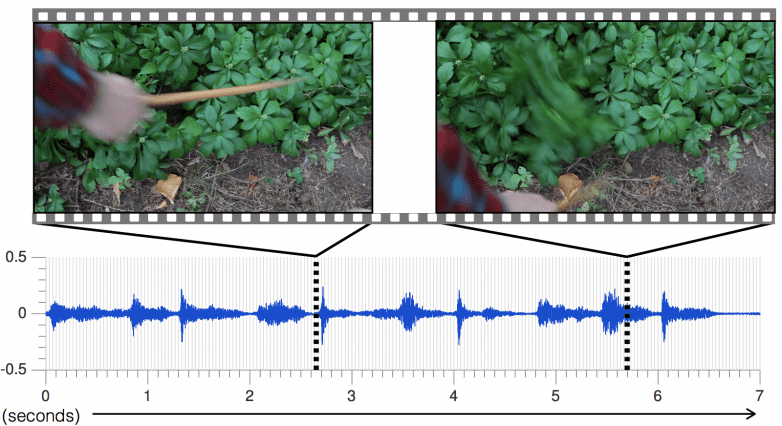
From the same Computer Science and Artificial Intelligence Laboratory (CSAIL) lab came another predictive artificial intelligence — this time for sound. What it does is basically produce a sound when shown a video of an object being hit.
The assigned sounds are realistic enough to fool a human viewer. When asked whether a sound was real or fake, human participants picked the fake sound over the real one twice as often as a baseline algorithm.
“When you run your finger across a wine glass, the sound it makes reflects how much liquid is in it,” says CSAIL PhD student Andrew Owens, who was lead author of the paper describing MIT’s CSAIL sound algorithm. “An algorithm that simulates such sounds can reveal key information about objects’ shapes and material types, as well as the force and motion of their interactions with the world.”
In other words, both algorithms are now learning in seconds what most humans have to learn in a lifetime: how people react, social norms, even what sound a drum stick makes when it hits a puddle of water.
Was this helpful?


