Computers today can’t make heads and tails of how our bodies usually move, so one team of scientists is trying to teach them using synthetic images of people in motion.

AIs and computers can be hard to wrap your head around. But it’s easy to forget that holds true from their perspective as well. This can become a problem because we ask them to perform a lot of tasks which would go over a lot smoother if they actually did understand us a tad better.
This is how we roll
Case in point: driverless cars. The software navigating these vehicles can see us going all around them through various sensors and can pick out the motion easily enough, but it doesn’t understand it. So it can’t predict how that motion will continue, even for something as simple as walking in a straight line. To address that issue, a team of researchers has taken to teaching computers how human behavior looks like.
When you think about it, you’ve literally had a lifetime to acquaint yourself to how people and other stuff behaves. Based on that experience, your brain can tell if someone’s going to take a step or fall over or where he or she will land after a jump. But computers don’t have that store of information in the form of experience. The team’s idea was to use images and videos of computer-generated bodies walking, dancing, or going through a myriad of other motions to help computers learn what cues it can use to successfully predict how we act.
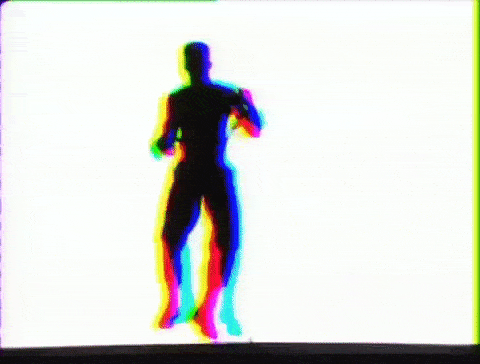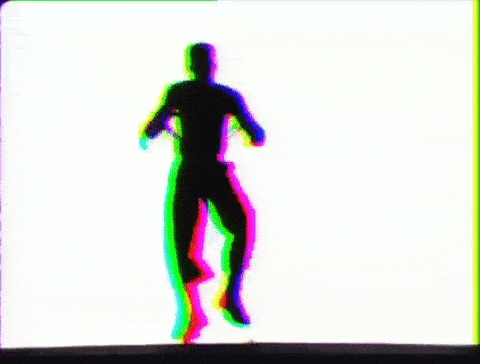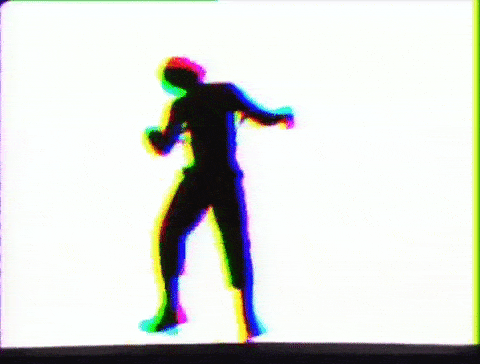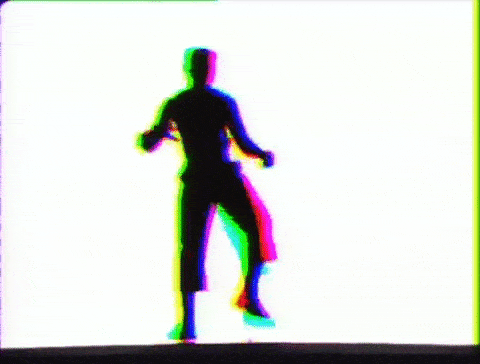
“Recognising what’s going on in images is natural for humans. Getting computers to do the same requires a lot more effort,” says Javier Romero at the Max Planck Institute for Intelligent Systems in Tübingen, Germany.
The best algorithms today are tutored using up to thousands of pre-labeled images to highlight important characteristics. It allows them to tell an eye apart from an arm, or a hammer from a chair, with consistent accuracy — but there’s a limit to how much data can realistically be labeled that way. To do this for a video of a single type of motion would take millions of labels which is “just not possible,” the team adds.
Training videos
So they armed themselves with human figure templates and real-life motion data then took to 3D rendering software Blender to create synthetic humans in motion. The animations were generated using random body shapes and clothing, as well as random poses. Background, lighting, and viewpoints were also randomly selected. In total, the team created more than 65,000 clips and 6.5 million frames of data for the computers to analyze.
“With synthetic images you can create more unusual body shapes and actions, and you don’t have to label the data, so it’s very appealing,” says Mykhaylo Andriluka at Max Planck Institute for Informatics in Saarbrücken, Germany.
Starting from this material, computer systems can learn to recognize how the patterns of pixels changing from frame to frame relate to motion in a human. This could help a driverless car tell if a person is walking close by or about to step into the road, for example. And, as the animations are all in 3D, the material can also be used to teach systems how to recognize depth — which is obviously desirable in a smart car but would also prove useful in pretty much any robotic application. .
These results will be presented at the Conference on Computer Vision and Pattern Recognition in July. The papers “Learning from Synthetic Humans” has been published in the Computer Vision and Pattern Recognition.
Was this helpful?


