A new algorithm developed at MIT can help spot signs of depression from a simple sample (text of audio) of conversation.

Depression has often been referred to as the hidden depression of modern times, and the figures seem to support this view: 300 million people around the world have depression, according to the World Health Organization. The worst part about it is that many people live and struggle with undiagnosed depression day after day for years, and it has profoundly negative effects on their quality of life.
Our quest to root out depression in our midst has brought artificial intelligence to the fray. Machine learning has seen increased use as a diagnostics aid against the disorder in recent years. Such applications are trained to pick up on words and intonations of speech that may indicate depression. However, they’re of limited use as the software draws on an individual’s answers to specific questions.
In a bid to bring the full might of the silicon brain to bear on the matter, MIT researchers have developed a neural network that can look for signs of depression in any type of conversation. The software can accurately predict if an individual is depressed without needing any other information about the questions and answers.
Hidden in plain sight
“The first hints we have that a person is happy, excited, sad, or has some serious cognitive condition, such as depression, is through their speech,” says first author Tuka Alhanai, a researcher in the Computer Science and Artificial Intelligence Laboratory (CSAIL).
“If you want to deploy [depression-detection] models in scalable way […] you want to minimize the amount of constraints you have on the data you’re using. You want to deploy it in any regular conversation and have the model pick up, from the natural interaction, the state of the individual.”
The team based their algorithm on a technique called sequence modeling, which sees use mostly in speech-processing applications. They fed the neural network samples of text and audio recordings of questions and answers used in diagnostics, from both depressed and non-depressed individuals, one by one. The samples were obtained from a dataset of 142 interactions from the Distress Analysis Interview Corpus (DAIC).
The DAIC contains clinical interviews designed to support the diagnosis of psychological distress conditions such as anxiety, depression, and post-traumatic stress disorder. Each subject is rated ,in terms of depression, on a scale between 0 to 27, using the Personal Health Questionnaire. Scores between moderate (10 to 14) and moderately severe (15 to 19) are considered depressed, while all others below that threshold are considered not depressed. Out of all the subjects in the dataset, 28 (20 percent) were labeled as depressed.
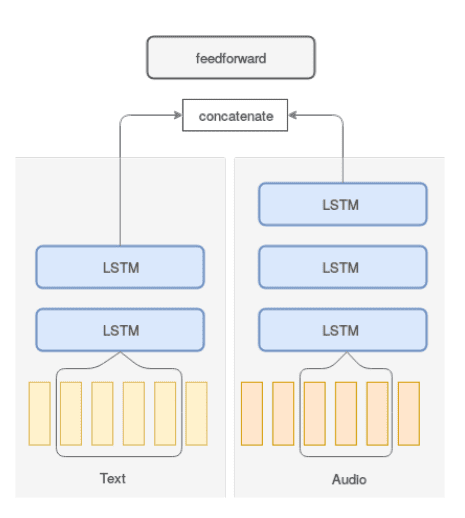
Image credits Tuka Alhanai, Mohammad Ghassemi, James Glass, (2018), Interspeech.
The model drew on this wealth of data to uncover speech patterns for people with or without depression. For example, past research has shown that words such as “sad,” “low,” or “down,” may be paired with audio signals that are flatter and more monotone in depressed individuals. Individuals with depression may also speak more slowly and use longer pauses between words.
The model’s job was to determine whether any patterns of speech from an individual were predictive of depression or not.
“The model sees sequences of words or speaking style, and determines that these patterns are more likely to be seen in people who are depressed or not depressed,” Alhanai says. “Then, if it sees the same sequences in new subjects, it can predict if they’re depressed too.”
Samples from the DAIC were also used to test the network’s efficiency. It was measured on its precision (whether the individuals it identified as depressed had been diagnosed as depressed) and recall (whether it could identify all subjects who were diagnosed as depressed in the entire dataset). It scored 71% on precision and 83% on recall for an averaged combined score of 77%, the team writes. While it may not sound that impressive, the authors write that this outperforms similar models in the majority of tests.
The model had a much harder time spotting depression from audio than text. For the latter, the model needed an average of seven question-answer sequences to accurately diagnose depression. With audio, it needed around 30 sequences. The team says this “implies that the patterns in words people use that are predictive of depression happen in a shorter time span in text than in audio,” a surprising insight that should help tailor further research into the disorder.
The results are significant as the model can detect patterns indicative of depression, and then map those patterns to new individuals, with no additional information. It can run on virtually any kind of conversation. Other models, by contrast, only work with specific questions — for example, a straightforward inquiry, “Do you have a history of depression?”. The models then compare a subject’s response to standard ones hard-wired into their code to determine if they are depressed.
“But that’s not how natural conversations work,” Alhanai says.
“We call [the new model] ‘context-free,’ because you’re not putting any constraints into the types of questions you’re looking for and the type of responses to those questions.”
The team hopes their model will be used to detect signs of depression in natural conversation. It could, for instance, be remade into a phone app that monitors its user’s texts and voice communication for signs of depression, and alert them to it. This could be very useful for those who can’t get to a clinician for an initial diagnosis, due to distance, cost, or a lack of awareness that something may be wrong, the team writes.
However, in a post-Cambridge-Analytica-scandal world, that may be just outside of the comfort zone of many. Time will tell. Still, the model can still be used as a diagnosis aid in clinical offices, says co-author James Glass, a senior research scientist in CSAIL.
“Every patient will talk differently, and if the model sees changes maybe it will be a flag to the doctors,” he says. “This is a step forward in seeing if we can do something assistive to help clinicians.”
Truth be told, while the model does seem very good at spotting depression, the team doesn’t really understand what crumbs it follows to do so. “The next challenge is finding out what data it’s seized upon,” Glass concludes.
Apart from this, the team also plans to expand their model with data from many more subjects — both for depression and other cognitive conditions.
The paper “Detecting Depression with Audio/Text Sequence Modeling of Interviews” has been published in the journal Interspeech.
Was this helpful?


