
Google, your favorite search engine and soon-to-be overlord of all human knowledge, just demonstrated one of the most impressive feats of software engineering. Exploiting the power of neural networks and an unrivaled database of trillions of photos, the Mountain View corporation showed that its possible to render a detailed, higher resolution image from a tiny, pixelated source, some only 8×8 pixels.
“Let’s enhance!”
It’s a classic moment in TV. Two special agents are gathered in front of a computer screen handled by a brainy technician. Finally, the agents get a glimpse of the suspect on a subway security cam. They instruct the technician to zoom-in on a patch. A pixelated image featured five people comes into focus. ‘Enhance!’ says Special Agent Smith. And they zoom and enhance again and again until they get a clear mugshot. ‘That’s our man’. And it only took 30 seconds. Kudos to law enforcement!
Problem is, in real life, you can’t do this as it would imply extracting more information from a limited source. Of course, there are plenty of image enhancing algorithms that do a pretty good job cleaning up blurry or grainy images. This sort of approach fills in the blanks so to speak but if your zoomed-in source is only a couple pixels wide there’s nothing you can do.
Google used a nifty trick, though, as you can notice in the image below. The first column is made of 8×8 sources, the middle column shows the images Google Brain was able to create from the pixelated source, and the third column shows the ‘ground truth’ or real depiction of what the 8×8 sources were to look like if they had been in higher resolution.

The way Google Brain handles this task is it first compares the 64-pixel source with other higher resolution images which were downsized to the same 8×8 grid. This is the conditioning neural network. The prior neural network then upscales and compares the 8×8 source against many real high-res images of celebrities and bedrooms, for this case study at least. The network then adds new pixels one by one in a way that matches what the machine already knows. In the case of an 8×8 block, a brown pixel on the far right and far left would correspond to eyebrows. When the image is scaled to 32×32, the blanks are filled with pixels that depict an eyebrow. The final image combines both conditioning and prior networks.
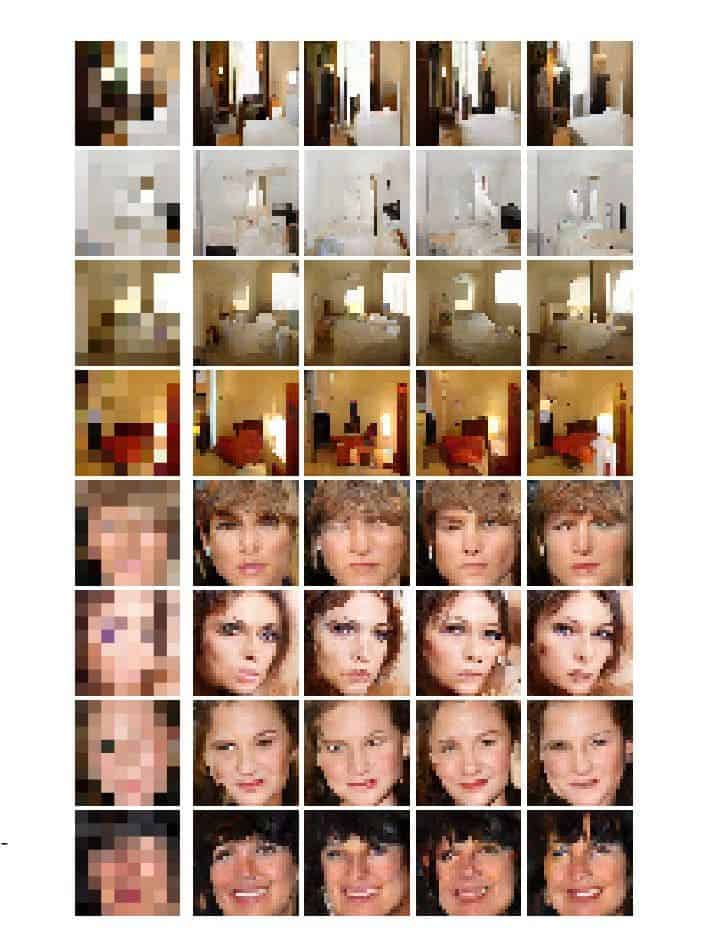
The resulting constructed (fake) images managed to fool quite a few people in tests that these were actually real images. Upscaled images of celebrities fooled 10 percent of human participants that these were genuine, where 50 percent would imply a perfect score. The bedroom images fooled 28 percent of humans. Bicubic scaling, a method that interpolates data points on a two-dimensional regular grid, didn’t manage to fool anyone.
That being said, the upscaled images made by Google Brain are fake. This is important to consider, else we might fall for it just like on TV. The upscaled images are educated guesses at best because, again, you can’t create more information from limited information. Some hunches are spot on, though, as evident in these press photos. Another consideration is that the networks knew they had to find a photo of a celebrity or bedroom which made the job a lot easier.
Police investigations and forensic scientists could make use of such a software, however, it would never stand in court. Rather, the “zoom-in, enhance” capability could offer a lead where there’s none to begin with. For now, at least, Google has no plans on turning this sandbox research project into something useful.
via Ars Technica
Was this helpful?


