
Deoxyribonucleic acid (DNA) is a long molecule that contains the hereditary genetic code required to build and maintain an organism. DNA sequences (the instructions inside the code) are converted into molecular messages that can be used to produce proteins. The DNA molecule is easily recognizable due to its double helix shape, consisting of two strands that wind around one another.
Ever wondered how to build a human? Like a cookbook, DNA contains all the necessary instructions in order to assemble a new organism. Although there are over a trillion cells that compose the human body, with varying degrees of complexity from neurons to immune cells, almost every one of these cells contains the same 3 billion DNA base pairs that make up the human genome.
Every species has a unique DNA sequence, and every individual also has slightly different DNA from the rest of the population (as long as they’re not clones that reproduce asexually).
What is DNA made of?
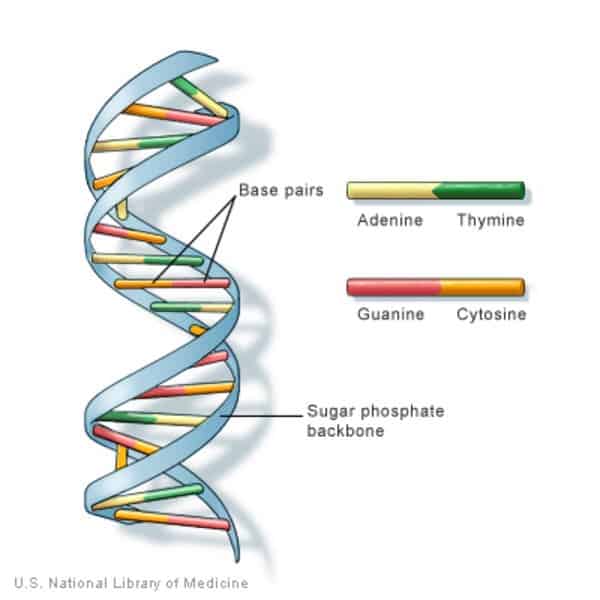
Each of the two DNA strands has a backbone made of alternating sugar (deoxyribose) and phosphate groups. Attached to each sugar is one of four types of nitrogen bases: adenine (A), thymine (T), guanine (G), and cytosine (C). These three parts together — a phosphate group, a sugar group, and a nitrogen base — are known as nucleotides.
The DNA double helix can be pictured as a sort of chemical ladder where the sides of the ladder are strands of alternating sugar and phosphate groups while the”rungs” are made up of two nitrogen bases, paired together by hydrogen bonds.
Base A always pairs with base T, and likewise C with G. Together, these units are called base pairs.
The sequence of nitrogen bases matters a lot. It can mean the difference between blue eyes or brown, tall or short, healthy or afflicted by a hereditary disease.
Overall, the complete instructions for a human contain three billion bases and about 20,000 genes found on 23 pairs of chromosomes, all wrapped inside a single molecule just six microns across located inside the nucleus of virtually every cell in the body.
Additionally, a small amount of DNA is present in the mitochondria, the structures within the cells that are responsible for converting the energy in food into a form that the cell can use — it’s called mitochondrial DNA (mtDNA). Together, the sum of all the DNA and mtDNA sequences in the cell is known as the genome.
If you uncoiled and stretched the DNA in one cell all the way out, it would be about two meters long. But what’s truly mind-boggling is that all the DNA in all your cells put together would stretch over a distance about twice the diameter of the solar system.
What does DNA do?
DNA sequences are used to make proteins in a two-step process. Enzymes first read the instructions in the DNA molecules in order to transcribe them into an intermediary molecule called messenger ribonucleic acid (mRNA). Pfizer’s and Moderna’s vaccines are based on mRNA, if that sounds familiar.
Next, the sequences in the mRNA molecules are translated into instructions that ribosomes, the small cellular structures responsible for making proteins, can ‘understand’. The protein-making machinery follows these instructions to the letter to link specific amino acids (protein building blocks) in the precise order required to produce a specific protein. The amino acids involved and the way they are linked to form the protein are what allow it to carry out its very specific tasks.
When a cell divides, so does DNA. Each strand of DNA in the double helix can serve as a pattern for duplicating the sequence of bases, so it can replicate and make exact copies of itself in the new cell. This copying process isn’t always perfect. Sometimes there is an alteration in the nucleotide sequence of the genome, called a mutation.
Each DNA sequence that contains the instructions for the production of a certain protein is known as a gene. Depending on how complex these instructions are, the size of a gene can vary from as little as 1,000 bases to one million bases in humans.
After the Human Genome Project was completed in 2003, scientists found that there were around 20,000 genes within the genome, a number that some researchers had already predicted.
But despite their fame, genes only make up 1% of the genome. The other 99% are instructions that regulate when and how these proteins are made. Scientists call this non-coding DNA because these sequences do not code for proteins.
At face value, the small number of genes relative to the entire genome might seem odd. But it makes sense when you consider that each of the over 200 cell types in the human body interprets a set of identical instructions (the genome) very differently in order to perform equally different functions.
Besides, a large genome doesn’t mean much. Plants in the genus Allium, which includes onions and garlic, have genome sizes ranging from 10 to 20 billion base pairs, whereas the human genome is only 3 billion base pairs. Obviously, a human is much more complex than an onion. This suggests that perhaps much of the genome isn’t actually useful and the size of a genome says nothing about how complex the organism is.
How do we know about DNA?
Since ancient times, people were at least somewhat aware that there was some hereditary factor that is passed down from parents to offspring. But it wasn’t until Gregor Mendel, a 19th-century monk, laid out the fundamental laws of inheritance that this process was unraveled scientifically.
Mendel was the first to demonstrate using his now-famous pea plant experiments that “invisible factors” — now known as genes — predictably determined the traits of an organism. He also coined many of the concepts and terms used in the field to this day, such as “recessive” and “dominant”.
DNA was actually known during the time of Mendel. The molecule was first discovered by Swiss biochemist Frederich Miescher in the late 1800s inside the nuclei of human white blood cells, but no one suspected that it had a central role in biology.
In the early 1900s, Russian biochemist Phoebus Levene, the author of over 700 papers on the chemistry of biological molecules, made phenomenal contributions to the unraveling of DNA. He was the first to discover the order of the three major components of a single nucleotide (phosphate-sugar-base), the carbohydrate component of RNA (ribose), and the carbohydrate component of DNA (deoxyribose), as well as the first to correctly identify the way RNA and DNA molecules are put together.
Levene’s work was expanded by Erwin Chargaff, an Austrian biochemist, who made additional discoveries surrounding DNA. He made two important contributions. First, he noted that the nucleotide composition of DNA varies among species. Secondly, he found that in almost all DNA, regardless of the organism or tissue it comes from, the amount of adenine (A) is usually similar to the amount of thymine (T), and the amount of guanine (G) usually approximates the amount of cytosine (C) — this now known as Chargaff’s rule.

These discoveries paved the way for the discovery of DNA’s double helix. In 1953, James Watson, Francis Crick, Maurice Wilkins, and Rosalind Franklin performed X-ray diffraction and built models showing the three-dimensional, double helix structure of DNA.
Watson and Crick used cardboard cutouts representing the individual chemical components of the four bases and other nucleotide subunits. The two scientists shifted the molecules around countless times, as though they were putting together a puzzle. However, the puzzle pieces never seemed to click until American scientist Jerry Donohue suggested that they make new cardboard cutouts for thymine and guanine. The different atomic configurations made all the difference and the two complementary bases finally fitted together perfectly. What’s more, the structure also reflected Chargaff’s rule.
Since then, the Watson and Crick model has suffered minor corrections, but its four main features remain the same to this day. These are:
- DNA is a double-stranded helix, with the two strands connected by hydrogen bonds. A bases always pair with Ts, and Cs always pair with Gs, which is consistent with and accounts for Chargaff’s rule.
- Most DNA double helices are right-handed, meaning the sugar-phosphate backbone curls around the axis of the helix counter-clockwise.
- The DNA double helix is antiparallel, which refers to the fact that the head of one strand is always laid against the tail of the other strand of DNA.
- Not only are the DNA base pairs connected via hydrogen bonding, but the outer edges of the nitrogen-containing bases are exposed and available for potential hydrogen bonding as well. These hydrogen bonds provide easy access to the DNA for other molecules, including the proteins that play vital roles in the replication and expression of DNA.
More recently, scientists have found that the precise geometries and dimensions of the double helix can vary. The most common configuration is the one outlined by Watson and Crick, known as B-DNA. But there is also A-DNA, a shorter and wider form that is usually found in dehydrated samples of DNA and rarely encountered under normal conditions. Lastly, there’s Z-DNA, which is a left-handed conformation and is a transient form of DNA that appears only during certain types of biological activity.







{kind=link}