A complex artificial intelligence program developed by DeepMind, a London-based company which was acquired by Google last year for $400 million, mastered classic ATARI video games, like Breakout, Video Pinball, and Space Invaders. It was so effective that it outperformed professional game testers in 29 of the 49 games it tried out. As is the case with such demonstrations, there’s more to it than just humiliating humans. The same algorithms could be used to develop and improve autonomous robots or self-driving cars.
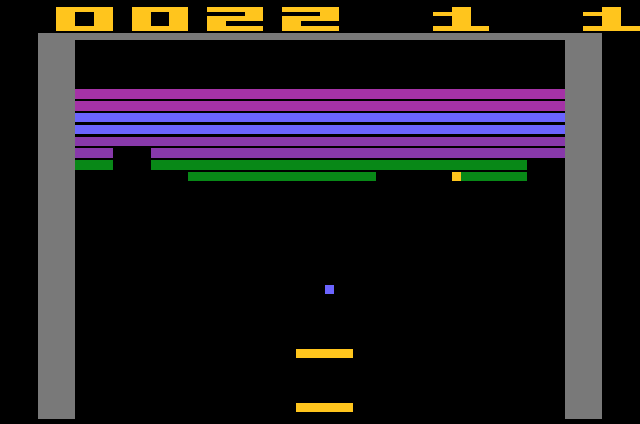
What’s so special about a computer program beating a human at video games? It’s a sensible question. A computer program which knows all the inner workings of a video game can navigate it with ease. It would be like a god, knowing beforehand whatever would happen in the game, because it knows all the sequence and has all the info. It’s the perfect deterministic universe. But the artificial intelligence written by DeepMind engineers played the game more like a human, than a computer program – it learned how to do it, step by step. The only information it was supplied for any of the 49 games were pixels, scores and available actions. That’s it.
This was possible using the deep Q-network (DQN) algorithm, which is actually a combo of two major architectures in machine learning: deep learning and deep reinforcement learning. Deep learning can already be found in a lot of software and, of course, web apps. This is how Google and Facebook know which ads to serve best, for instance. Deep reinforcement learning is a bit difference since it involves making the software better and better with each instance by employing a system of rewards. Doggy, sit. Good, boy!
“Strikingly, DQN was able to work straight ‘out of the box’ across all these games,” DeepMind’s Dharshan Kumaran and Demis Hassabis wrote in a blog post.
IBM’s Deep Blue or Watson, the supercomputer programs which beat Garry Kasparov at chess and record holding Jeopardy! champions, respectively, are often heralded as being at the cutting edge of artificial intelligence. Put Deep Blue out of its chess framework, however, and it’s like a fish out of water. DQN is different. It’s versatile and can adapt to multiple objectives. Sure, it’s like a fish out of water too, but not for long. It struggles and struggles until it grows lungs. Check out the video below to get an idea of how DQN mastered Breakout (via BBC).
DQN wasn’t all that good in all kinds of video games. It behaved marvelously when faced with instantaneous decision making, like when playing pinball. When it had to plan long-term – climbing down ladders and then jumping skeletons in order to retrieve keys in Montezuma’s Revenge, for instance – it behaved very poorly. DeepMind engineers are confident they can make the algorithm even better and hope that in 18 to 24 months they can implement it in real-life situations. Google’s self-driving cars are already amazing, and with DQN these could turn out even better. Machine learning shines when matched with robotics, though. Google didn’t buy Boston Dynamics for nothing. It’s all part of a greater scheme it seems. Ultimately DQN, and others like it, could make its greatest contribution by teaching us about ourselves.
” [..] it may even help scientists better understand the process by which humans learn,” Kumaran and Hassabis said, citing physicist Richard Feynman, who famously said, “What I cannot create, I do not understand.”
The algorithm and its video game performance were detailed in a paper published in Nature.






{kind=link}